Introduction
This week, in order to get the direct sense of whether we are in the good direction, I am going to set up the benchmark environment and a baseline with our original NSpM model.
Benchmark environment
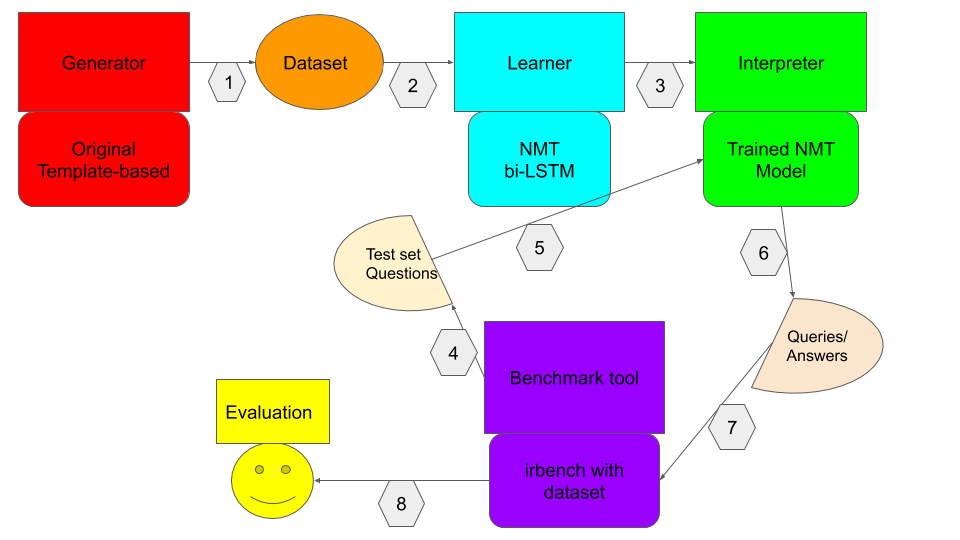 Figure1: The whole benchmark pipeline
Figure1: The whole benchmark pipeline
This figure could give you a first impression of our benchmark process. We have selected irbench as our benchmark tool. Although Geribil may be more mature, but it is an online platform, and irbench is stabler as it could be set up locally.
Evaluation Metrics
We will principally evaluate our NSpM model with two metrics, f-score and BLEU score.
F-score
f-score aims to evaluate on the retrieved answers, this metric ignores the performance of the NMT model cares only about the final results.
In our context, a FP is a wrong answer and a FN is a missed answer. For example:
Query ‘list all scandinavian countries’ returns
:Denmark,:Norway,:France:Franceis a FP (wrong):Swedenis a FN (missing)
This f-score metric is integrated in the irbench.
BLEU score
A BLEU score could be accompanied with the f-score, it evaluates the quality of the translation. Imagine that two different questions could give the same answer, so we could never say if the model learns will with only the metric f-score.
Normally, the NMT model will automatically calculate this score while training, but it’s still possible if we wants to calculate the BLEU score on the test set. The only problem is that the SPARQL queries interpreted by oud Interpreter are equipped with the complete URIs while the gold queries given by test set of irbench are equipped with PREFIX and abbreviations:
Gold query: PREFIX dbo: \http://dbpedia.org/ontology/ PREFIX res: \http://dbpedia.org/resource/ SELECT DISTINCT ?name WHERE { res:Queens_of_the_Stone_Age dbo:alias ?name }
System query: SELECT DISTINCT ?name WHERE { \http://dbpedia.org/resource/Queens_of_the_Stone_Age dbo:alias ?name }
irbench tips
If you also want to set up a benchmark environment with irbench, here are some tips to run the jar:
I recommend to run it with jdk8, if not, this will cause java.lang.NoClassDefFoundError: javax/xml/bind/JAXBException in higher version, this could still be resolved in JDK 9/10 by adding --add-modules java.xml.bind as an argument in run configuration, or this removed class could be only manually added in pom.xml.
As we have only a release version of jar file, this could only be run with jdk8/9/10. (I have run it with jdk14 and failed, and succeeded with jdk8, the solution for jdk9/10 is what I found from this stackoverflow question)
To run the jar:1
java -jar <released_jar_name> -evaluate <datasetID> <path of your results file> "<Metric ID>"
Make sure the json of your results file should be coherent with the test set json.
An example:1
java -jar irbench-v0.0.1-beta.2.jar -evaluate "qald-9-test-multilingual" "<yourpath>/qald-9-NSpM-test.qald.json" "f-score"
Pseudo Baseline
I call it a pseudo baseline because we haven’t discussed on the details in order to set up the baseline, and I’ve just made an naive experiment to test if my Benchmark environment works well.
Here are some details to be recorded:
Training dataset
I’ve directly used the dataset of Monument_300 which is proposed in the readme of NSpM project. It’s handy to use and not too big to train the model on my Mac.
Test set
I’ve used all the english question in qald-train-multilingual.qald.json.
Results
The BLEU score on our own dataset(validation set) is relatively high, 86.9/100.
But the result of f-score on test set is terrible, 0 f-score on average, but this is normal because our training set is really restricted to the domain of Monument but the test set questions are more opened(I used the word ‘opened’ but to be noted, there are still in restricted domain but not open-domain questions ).
One problem is that I found some queries are not grammarly correct, which means the could only retrieve a Bad Request 400 from the SPARQL endpoint.
Another point to be noted is that the prefix are not correctly used as below:
SELECT DISTINCT ?name WHERE { \http://dbpedia.org/resource/Queens_of_the_Stone_Age dbo:alias ?name }
We could see that the resource is represented by the complete URI but the Ontology is represented by its abbreviation, and this is not a unique case. This could be caused by the rules for generating the templates in Generator.
Some thoughts
We could see that only one domain data-set could not train a satisfactory QA model to response to relatively open questions, so it becomes problematic to select domains so in order to generate a relatively complete data-set which can handle questions most domains.