Introduction
Last week, I’ve set up a pseudo baseline with 0 f-score, so this week, I will be principally working on the set up of a real baseline and benchmark.
As we have discussed in last Thursday’s meeting, choosing the proper ontology terms to cover all the queries in qald-9-train will be crucial. To start with, we will only focus on the simple Basic-Graph-Pattern queries
Strategies of creating data set
We follow the strategy for the data:
- Top-down by using QALD-9 queries from experts
- Bottom-up by creating templates from data itself
And I’ve got two approaches to execute this strategy:
Approach 1
- Extract all the ontology terms that appear in the
QALD-9data set. Most of the ontoloies are of type Property, not of type Class, so we will need to query DBpedia base to get their Domain Class, like Class Person for Property education.- Use Anand’s pipeline and these ontology terms of Class to generate our template set.
This approach has a disadvantage, which I will be discussing in detail in the next section, that is it will create a really huge template set, with 26 ontology terms, 1000+ templates, which will generate a size of 440k data set. This huge and heterogeneous(26 ontology terms) training set is almost impossible to be learnt.So I came up with another approach.
Approach 2
This approach follows the first two steps of approach 1, and a third step
3.Filter the template set, to eliminate all the templates with ontology that doesn’t appear in ‘QALD-9’ data set. This will reduce dramatically the size of training set(from 440k to 43k).
But this approach didn’t work neither because of the multiple ontology terms, so at last I tries with only one Ontology which is the most concerned inQALD-9, like ‘Person’ and ‘Work’.
Troubles encountered
The Neural Machine Translation(nmt) model has encountered some troubles during training, resulting a low BLEU score(around 65). I will present these troubles and what I have done to overcome some of them, or try to find out the reasons why these issues occurred and the potential solutions.
Token sep_dot
The token
select ?x where{dbo:pdb . . . }
As we are dealing with single-BGP queries, therefore dots are not supposed to appear in our SPARQL at all, because
SELECT DISTINCT ?uri WHERE { res:Area_51 dbo:location ?uri . ?uri dbo:country res:United_States. }
I found that this issue is cause by the proper noun like Washington D.C., the last dot is wrongly identified as a
So we decided to clean the data by eliminating all the queries with
After directly solved this issue(by cleaning the data), I also modified the base code to avoid this issue in the future.
Entity Mis-linked
Entity linking in our context of KGQA is the task of deciding which KG entity is referred to by (a certain phrase in) the NL question. Entity linking is considered as a subtask in the process of question answering, but as we are using NMT model, translation based systems (see Section 4.3) in principle could generate the whole query in a single sequence decoding process, thus solving all subtasks at once. As a result, we could not specifically solve this entity mis-linked problem separately.
The issue could be showed as the examples below:
src: What is the building end date of 50 kennedy plaza ?
ref: select var_x where brack_open dbr_50_Kennedy_Plaza dbo_buildingEndDate var_x brack_close
nmt: select var_x where brack_open dbr_Giebelstadt_Army_Airfield dbo_buildingEndDate var_x brack_closesrc: Who discovered Pluto?
ref: SELECT ?uri WHERE { dbr:Pluto dbo:discoverer ?uri }
nmt: SELECT ?x where{http://dbpedia.org/resource/819_Barnardiana dbo:discoverer ?x }
Failed attempts
Consequently, I’ve thought to solve this issue straightway by adding more train_steps and number of units, and hopefully this more complex model could learn the linking relation between a String and an entity. But unfortunately, this doesn’t solve the problem. The BLEU score is always around 65. Empirically, a BLEU score greater than 80 means that the model has learnt the linking relation.
I’ve then decided to filter the data by eliminating all the irrelevant templates, i.e. keeping only the templates that contain the properties which appear in the qald-9-train data set.(Approach2 that I’ve presented) I though that reducing the size of data set could help with the mis-match problem, but this doesn’t help(BLEU score still around 65). And I thought it could be caused by the multiple ontology terms we used, so I tried with single ontology template set, like Person and Work, this time, the BLEU score could reach a relative satisfactory level(greater than 80 around 12000 steps for dbo:Person, and 72 at 20000 steps for ontology dbo:Work )
Reason for the mis-linking and some thoughts
The NMT model has been proved to be successful(even it might not be the best model today) for Machine Translation domain, our NSpM model is also proved to be mature.
The problem is an entity in a SPARQL query is usually “longer”, which means for example, a human’s name “William Henry Smith” in the natural language is represented by “dbr_William_Henry_Smith” or even longer “dbr_William_Henry_Smith_(American_politician)”. This three words name is converted to a single word entity, so this time we need to translate correctly all the three words so that the loss could get improved, a single error like “dbr_William_Henry_Jack” is not accepted and means no improvement. This means, for NL2SPARQL task, the NMT model will need more effort and chance to learn something(especially an entity name) to reduce the Loss than a normal NL2NL task(like french2english).
This is ok when we just have one ontology of entities, for example, in order to generate the data set of ontology Person, we use approximately 600 entities of Person for each template on average. This means the NMT model need to learn the combination between 600 entities and 600 phrase in the NLQ. This even get worse when we are training with multi-ontology data set. Imagine the dramatic increase of the number of combinations. ontology means combinations. This may not be mathematically correct, but this could give the intuition of how much harder it will be if we involve more ontology. Here come three Figure 1,2,3 for more intuition.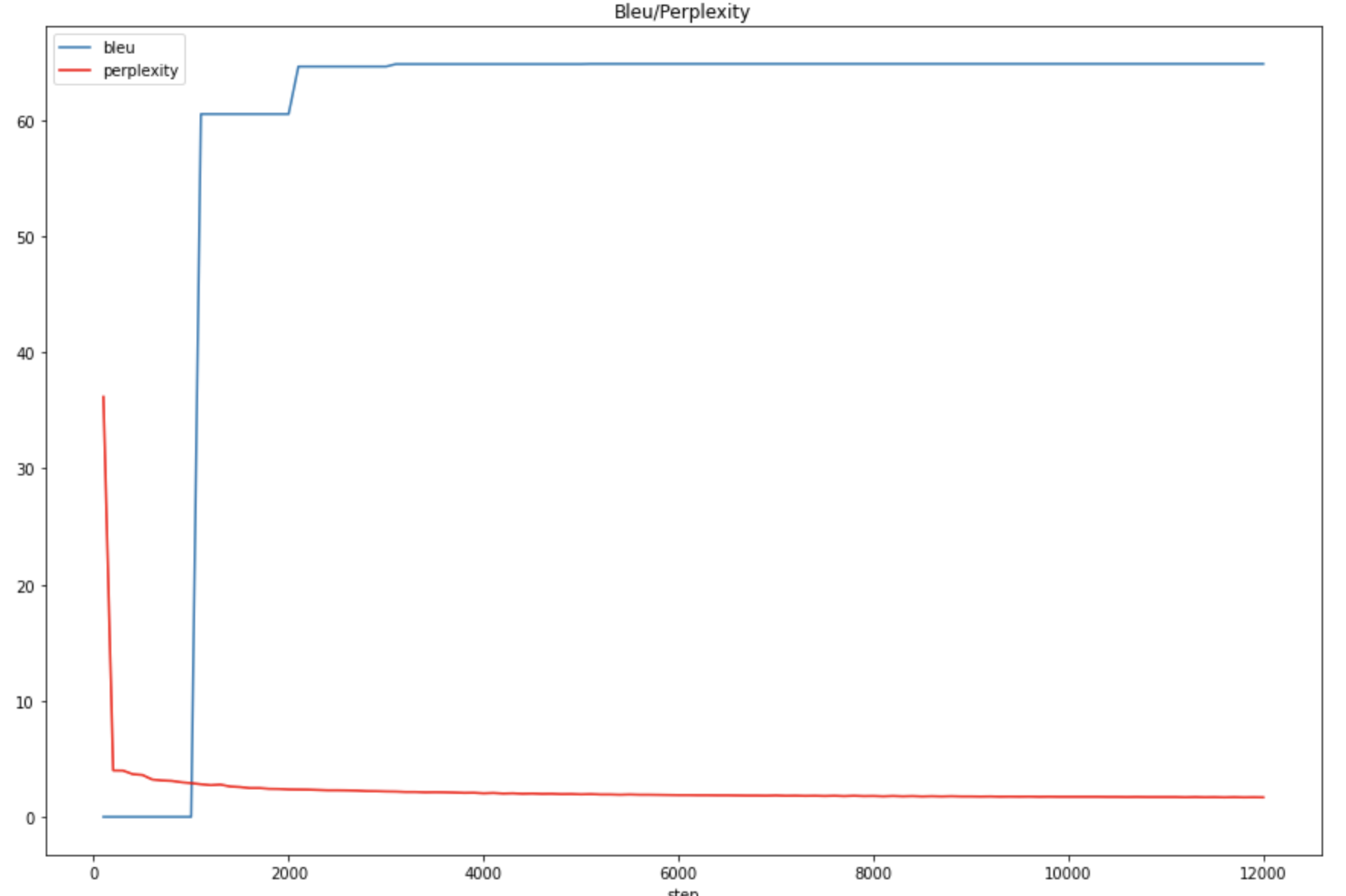 Figure1: The BLEU/Perplexity score for multiple ontology training
Figure1: The BLEU/Perplexity score for multiple ontology training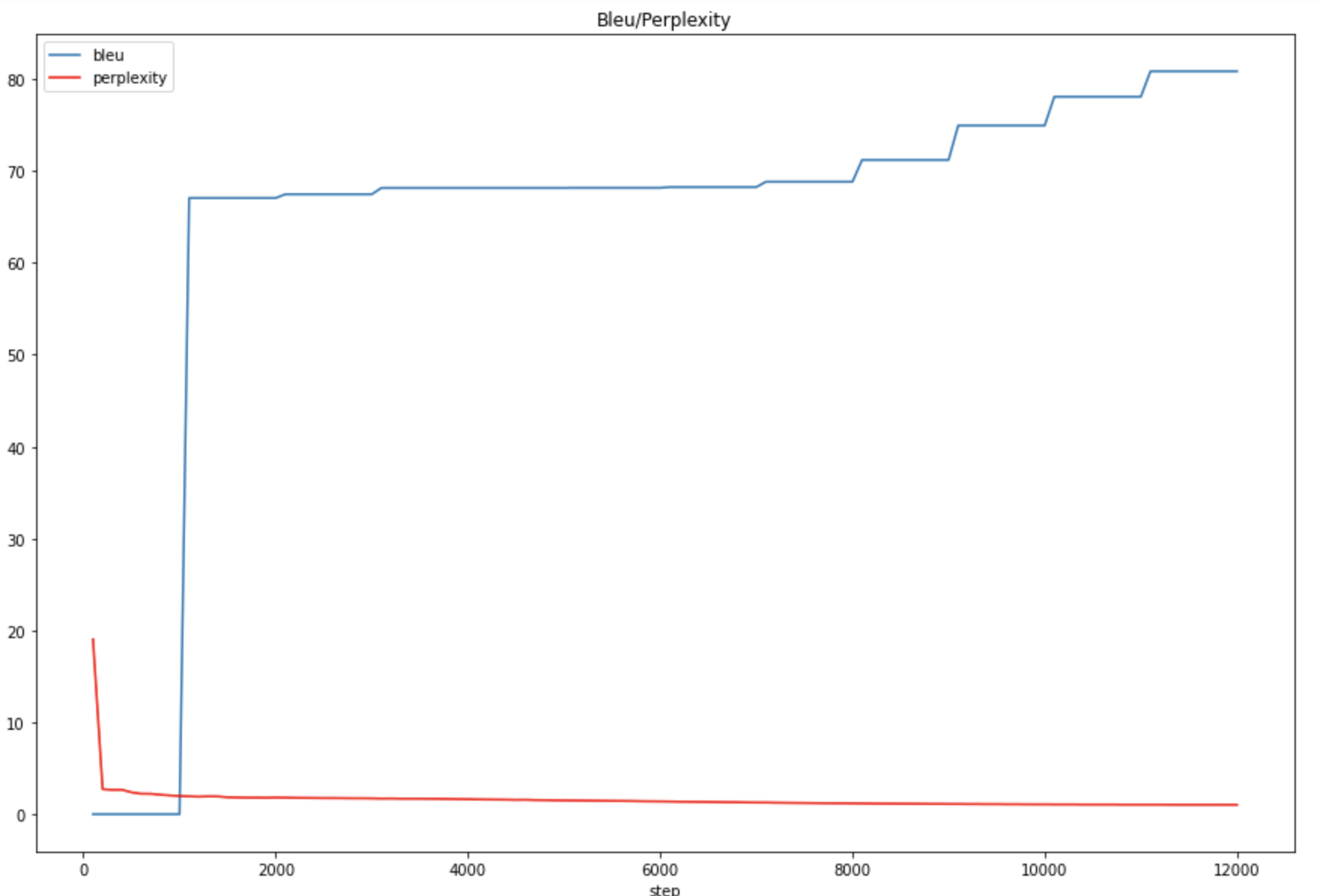 Figure2: The BLEU/Perplexity score for single ontology (Person) training
Figure2: The BLEU/Perplexity score for single ontology (Person) training Figure3: Comparison of BLEU score between Multiple ontology and single ontology
Figure3: Comparison of BLEU score between Multiple ontology and single ontology
These three figures could show that, the model usually learn well the matching of predicates(relation) around 1000 steps, where we could see a jump of BLEU score. But then, to learn the entity linking, it’s tough. We can see that even for a single ontology Person, the model begins to learn something from 8000 steps to 12000 steps. But for multiple ontology, it doesn’t learn anything at all before 12000 steps, and even until 36000 steps, it learns nothing(an experiment I’ve realised after).
Even at last, I choose only one single ontology, like dbo:Person or dbo:Work to generate the template set, I still got zero f-score. I’ve compared the our predicted SPARQLs with the golden ones, some times, it’s caused by a mis-matched predicate, but most of the time, it’s the mis-linked entity. What is surprising is that, many of the entities appear in ‘QALD-9’ doesn’t even appear in our training set, so we have zero chance to respond to those questions.
Another note to be pointed out is that, I found many of the structure of questions in QALD-9 have never appear in our template-based data set, which means the training set and testing set have a really different distribution in terms of question structure. Like: “Give me a list of all trumpet players that were bandleaders.”, this kind of question isn’t concluded by any of our template.
Conclusion with my Paraphrasing strategy and further direction
After these failed attempts, I began to think about my paraphrasing strategy. Even QALD-9 isn’t a data set of good quality, but as we are just using it to test our model to set up a baseline, we could consider it as the real questions asked by users. In this case, which issues mentioned above could be solved by the Paraphraser:
1. Mis-matched predicate
This would be the issue that could most possibly be solve with the Paraphraser. But this issue isn’t the most problem that I have encountered.
2. Mis-linked entity(object)
This is the most encountered problem, but unfortunately, we will only process the paraphrasing at the phase of templates generation, where entities are represented by a placeholder.
This could be solved by adding more hidden units, layers and training steps, but this will need a lot time to be proved.(16 hours for a 2 layer-LSTM 1024 units model and 36k training-steps). Another way, which is still in theory in my head, is to add an entity-linking phase to our NSpM model, and to use another approach to replace the NMT model.
3. Different question/query structure
This is possible to be solved by the paraphrasing if only the question structures are different and impossible if the query structures are also different.
Adding more rules to generate template could be straightway to solve this issue. Meanwhile, it’s also interesting to implement a continuous-learning approach to automatically learn new templates, but this would probably need a User feedback system.
At last, I want to say that to simply set up the benchmark and a baseline, changing the data set may be easier. But to improve our NSpM model, these directions could all be considered.