Introduction
This week, I’ve firstly trained another model with only the original questions using the 300d Glove embeddings. Then I principally worked on the “One-command pipeline”.
300-dimension GloVe without Paraphraser
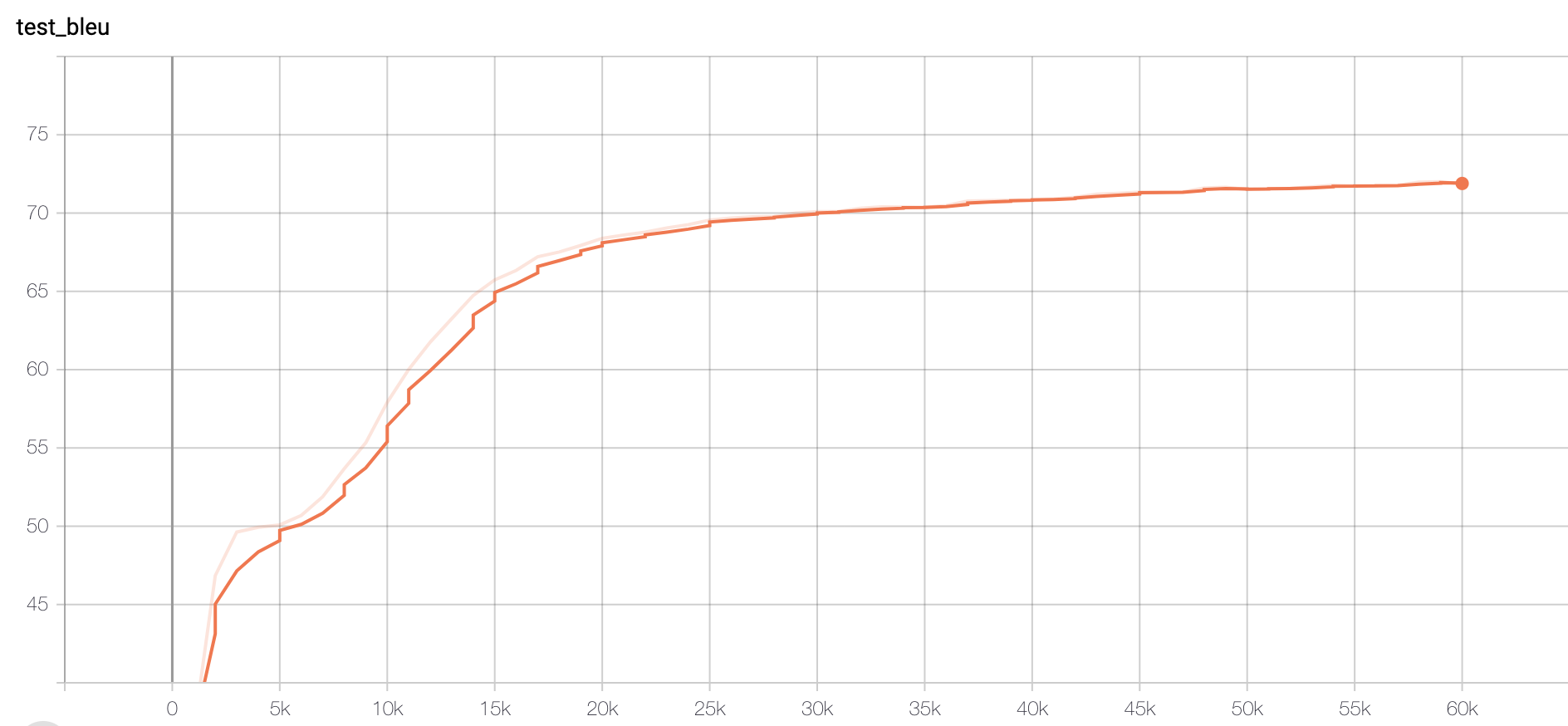
Figure 1. Bleu score 71.89
Figure 2. Accuracy 0.385
Compared to the accuracy of 50-d GloVe model, which reached 0.365, we could see that a larger dimension of embeddings could help with the performance(0.365 -> 0.385), but not as much as the Paraphraser(0.365 -> 0.483).
The complete pipeline
The complete pipeline could be divided into 4 principal steps and several detailed steps as below:
1.Templator: Generation of templates
2.Paraphraser: Batch-Paraphrasing2.1 Download BERT-Classifier
2.2 Launch Paraphraser3.Generator: Generation of corpus and data sets
3.1 Generate data.en/sparql
3.2 Generate vocab (simple tokenizing and normalization)
3.3 Generate Glove embeddings3.3.1 Download GloVe 300d pretrained model
3.3.2 Fine-tune en and Train sparql4.Learner: NMT training
4.1 Split into train/dev/test
4.2 Training with embedding
The code has already been tested separately locally on my Macbook, but I noticed that some Shell’s commands are slightly different between GNU/Linux and Mac OS, like the different option of command sed. In case that there may be other differences or issues happened on a Linux server, I would also try running the pipeline shell in a linux environment.
Conclusion
The work has nearly reached an end, the next step will be running the complete pipeline on the whole ontology classes of DBpedia.