Introduction
Last week, we discussed about the failed attempts to set up the baseline with multiple ontology terms. As we still considered it necessary to cover as many utterances of NL question as possible, trying to handle well all of the other issues before really start a time-consuming training is a good idea.
Embeddings of words is the option that we decided to deal with this week.
Embedding of Input and Output
As the NMT model support pre-trained word embeddings, but only if we use them on both sides, i.e. we need embedding both natural language and Sparql query.
GloVe embedding
The GloVe proposes its pre-trained embedding so that we could simply use them as the input of the NMT model.
Unlike other pre-trained embedding models using language model, GloVe uses the Co-occurrence matrix:
: The co-occurrence matrix
: In the whole corpus, the number of times that the word i and the word j appear together in a window
: The two word vectors
: The bias
Fine-tune GloVe model
In our case, we may have a data-set whose vocabulary has a large number of words that are not present in pre-trained model, this may cause a serious OOV issue. Fortunately, the GloVe model could be fine-tuned, this is also why we don’t choose Word2Vec embedding. Here, I followed the article to fine-tune the GloVe embeddings.
Once fine-tuned, the new embeddings are compatible with the existing embeddings it makes sense to use a mixture of the two embeddings.
Improvement of model training
After some adjustments, I have succeeded to run the NMT model with our trained GLoVe embeddings. Here is the figure that shows the two curves of BLEU score along the training steps:
The blue curve shows the progress of the model without pre-trained embeddings, the red one shows our model with word embeddings.
It’s a little bit surprised to see that the embeddings does not accelerate the training of NMT, it falls behind in the first 17500 steps, but it shows the possibility to improve along with the train steps.
Conclusion
We are using fixed word-embeddings because the NMT model does not support contextualized embeddings like BERT, ELMo, but I think it will be a good choice in the future if we change our base of Translation Model.
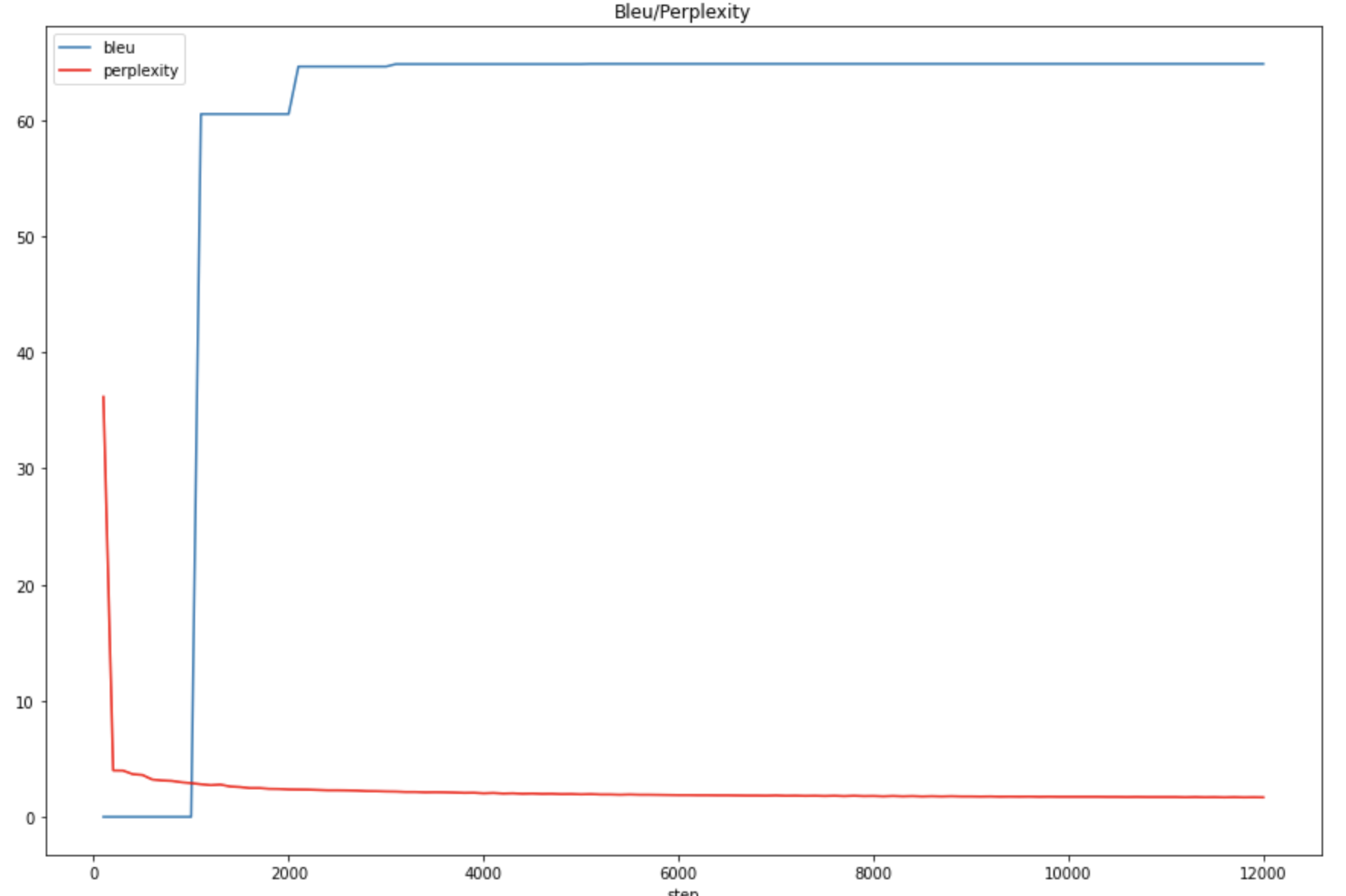 Figure1: The BLEU/Perplexity score for multiple ontology training
Figure1: The BLEU/Perplexity score for multiple ontology training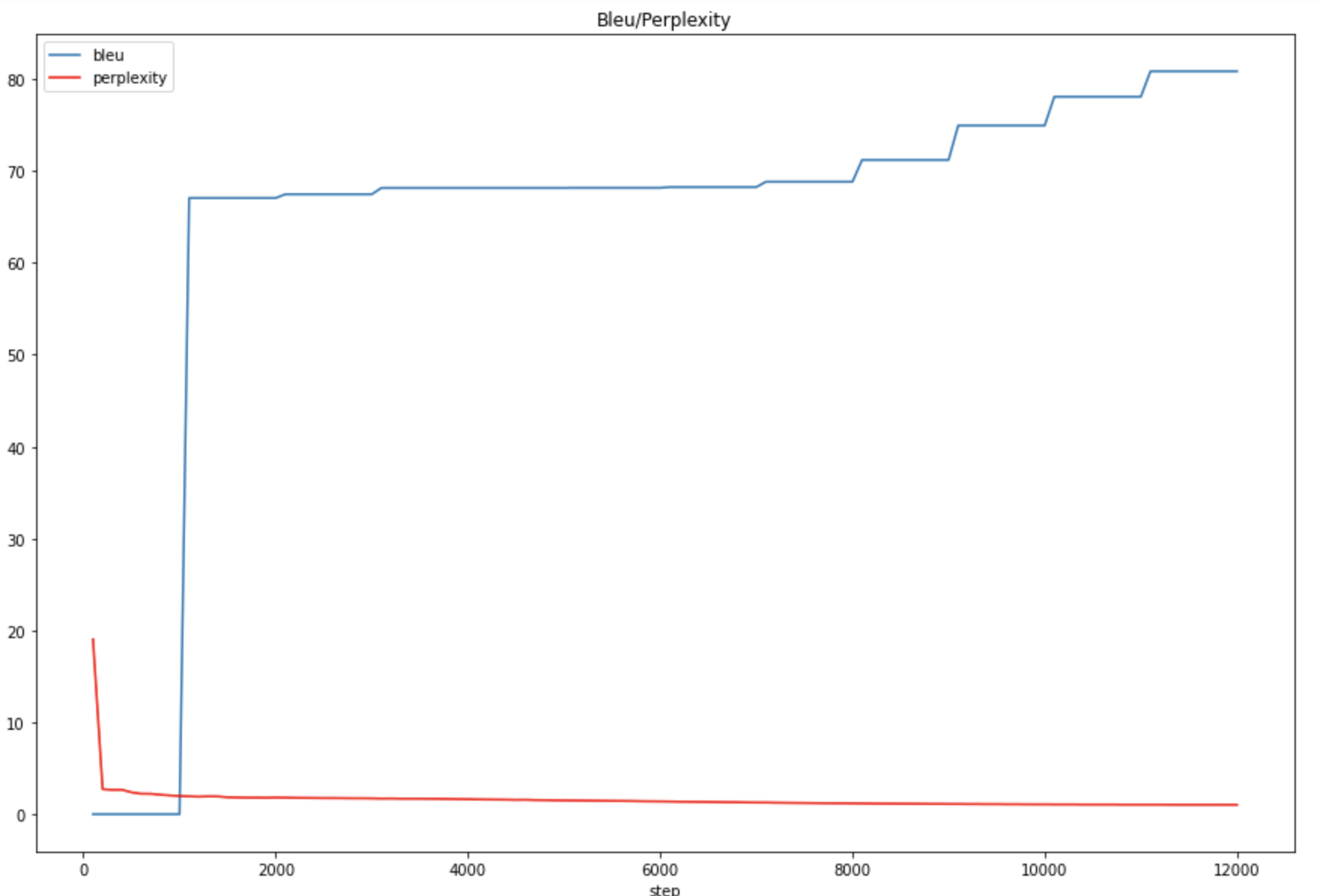 Figure2: The BLEU/Perplexity score for single ontology (Person) training
Figure2: The BLEU/Perplexity score for single ontology (Person) training Figure3: Comparison of BLEU score between Multiple ontology and single ontology
Figure3: Comparison of BLEU score between Multiple ontology and single ontology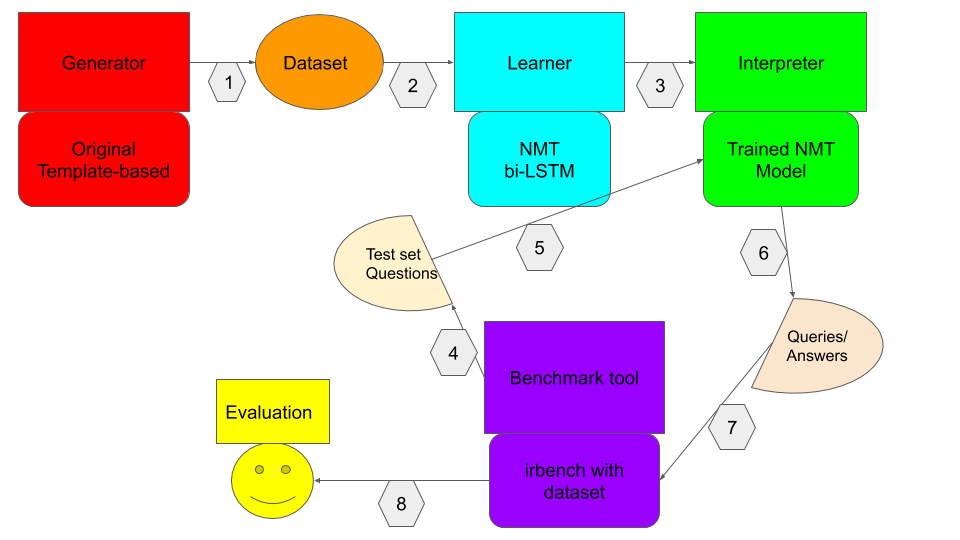 Figure1: The whole benchmark pipeline
Figure1: The whole benchmark pipeline Figure1: New question template will be generated by our Paraphrase Model and hopefully be matched with the same Query template
Figure1: New question template will be generated by our Paraphrase Model and hopefully be matched with the same Query template