Why the Paraphraser could increase the performance
We’ve seen the improvements of performance on a DBpedia based data set and a Yado based data set thanks to Paraphraser. But why it could improve the accuracy with the same trainings steps and the same model (Bi-LSTM) comparing with a data set without Paraphraser?
Hypothesis 1
It increases the amount of templates for each relation and entity (Tripling the template size), so each entity and relation have more examples to be learnt.
Experiment 1
Copy the templates 2 times in plus, so the size of templates equals to the ones with Paraphraser.
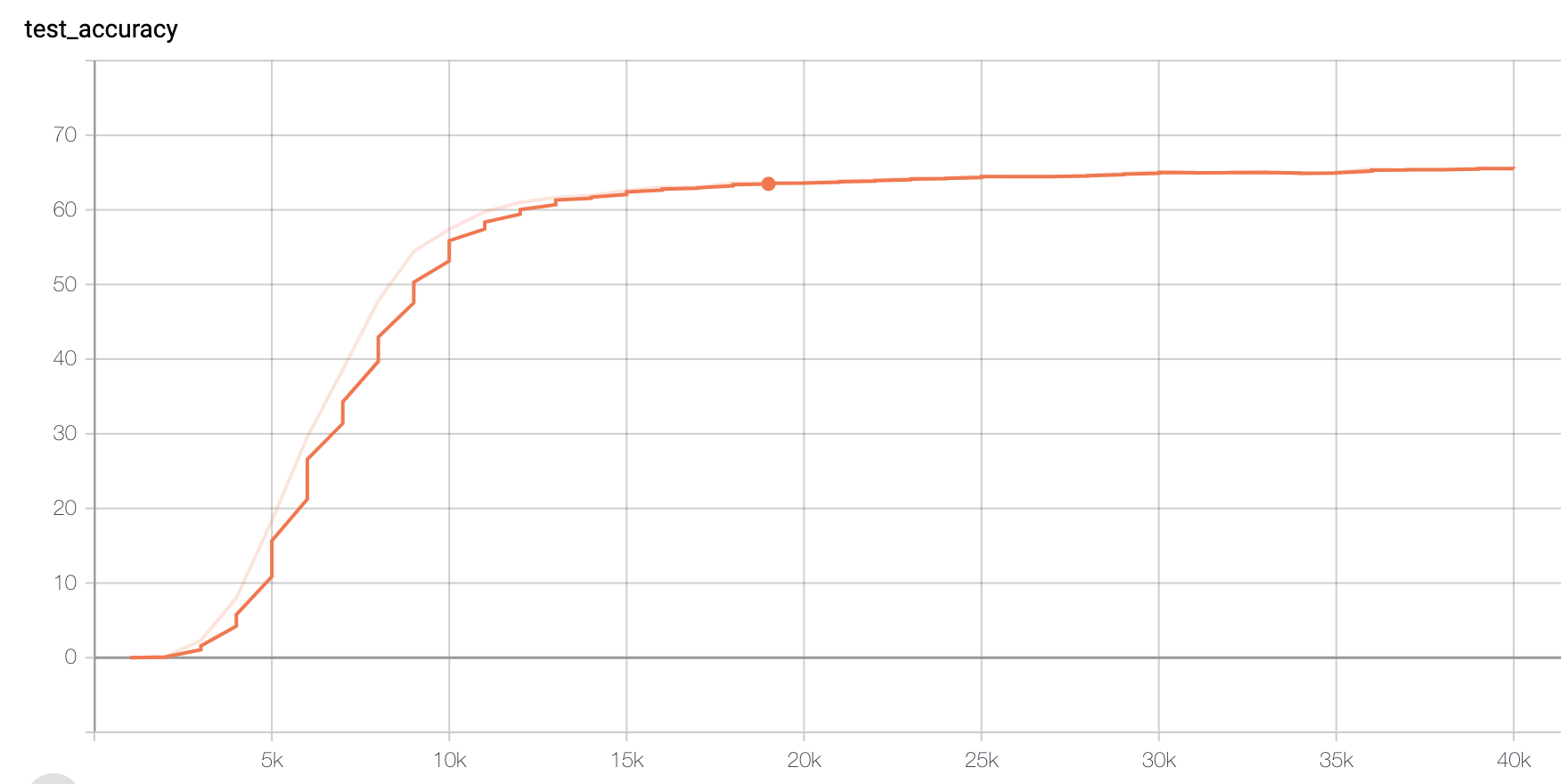
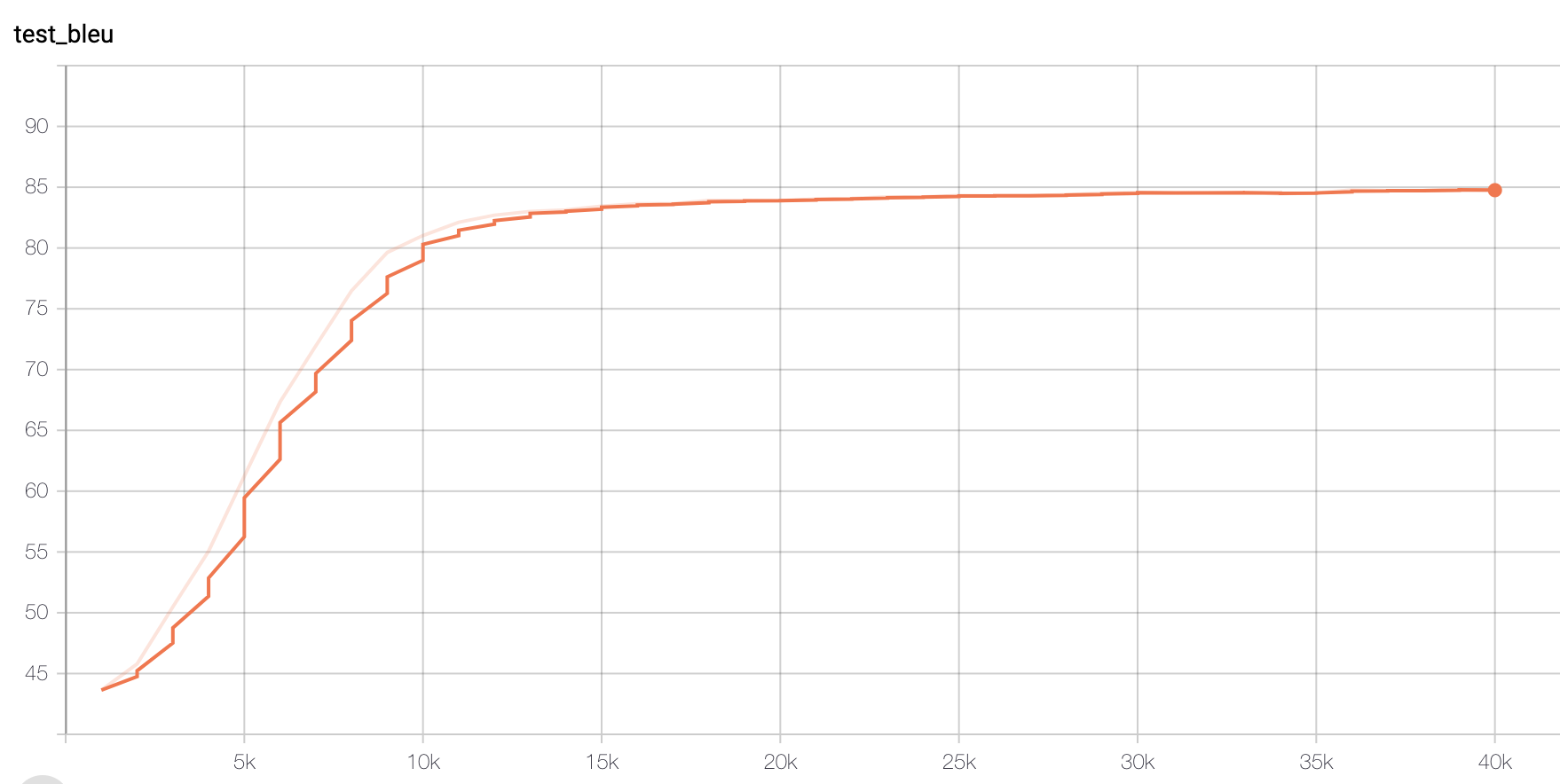
Result of Accuracy:
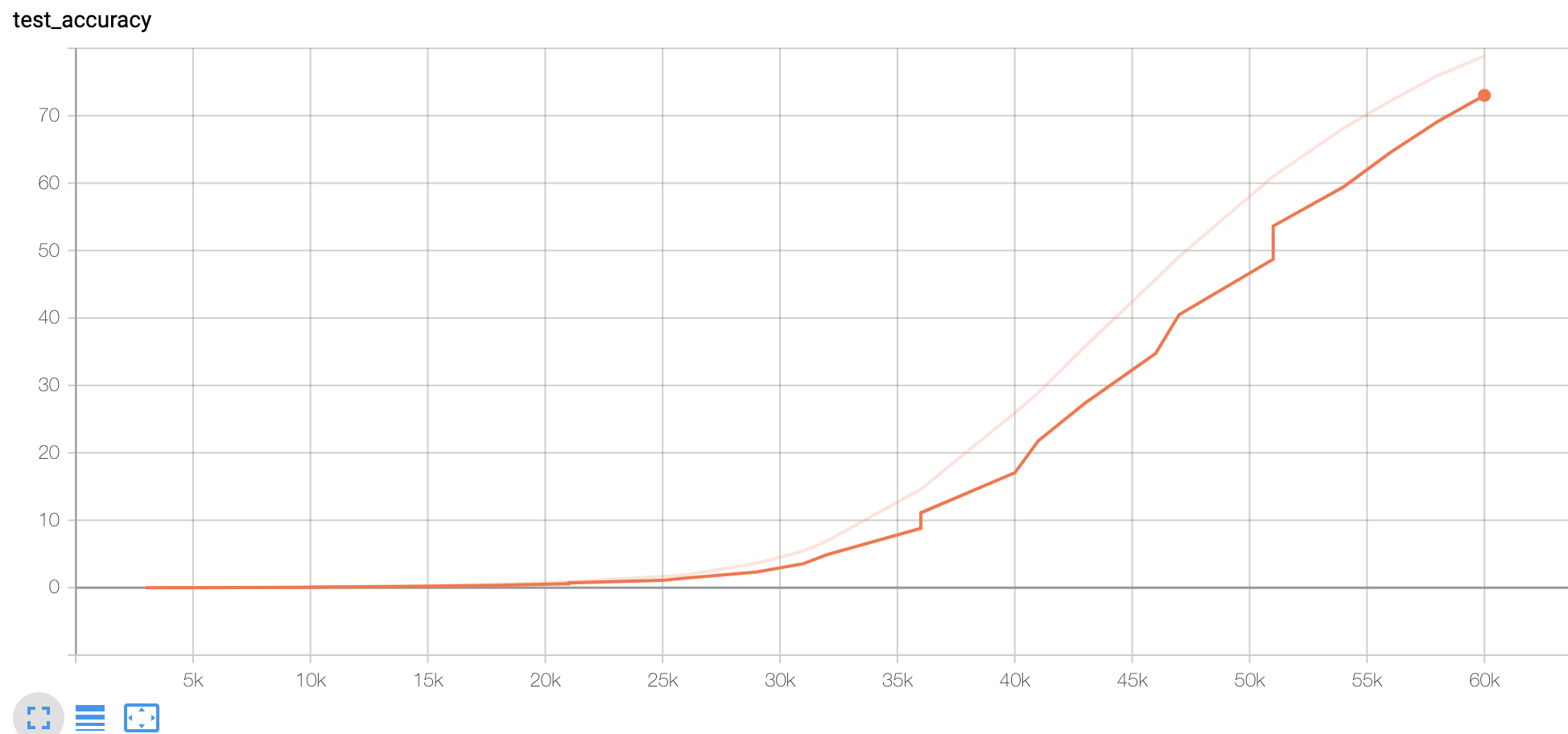
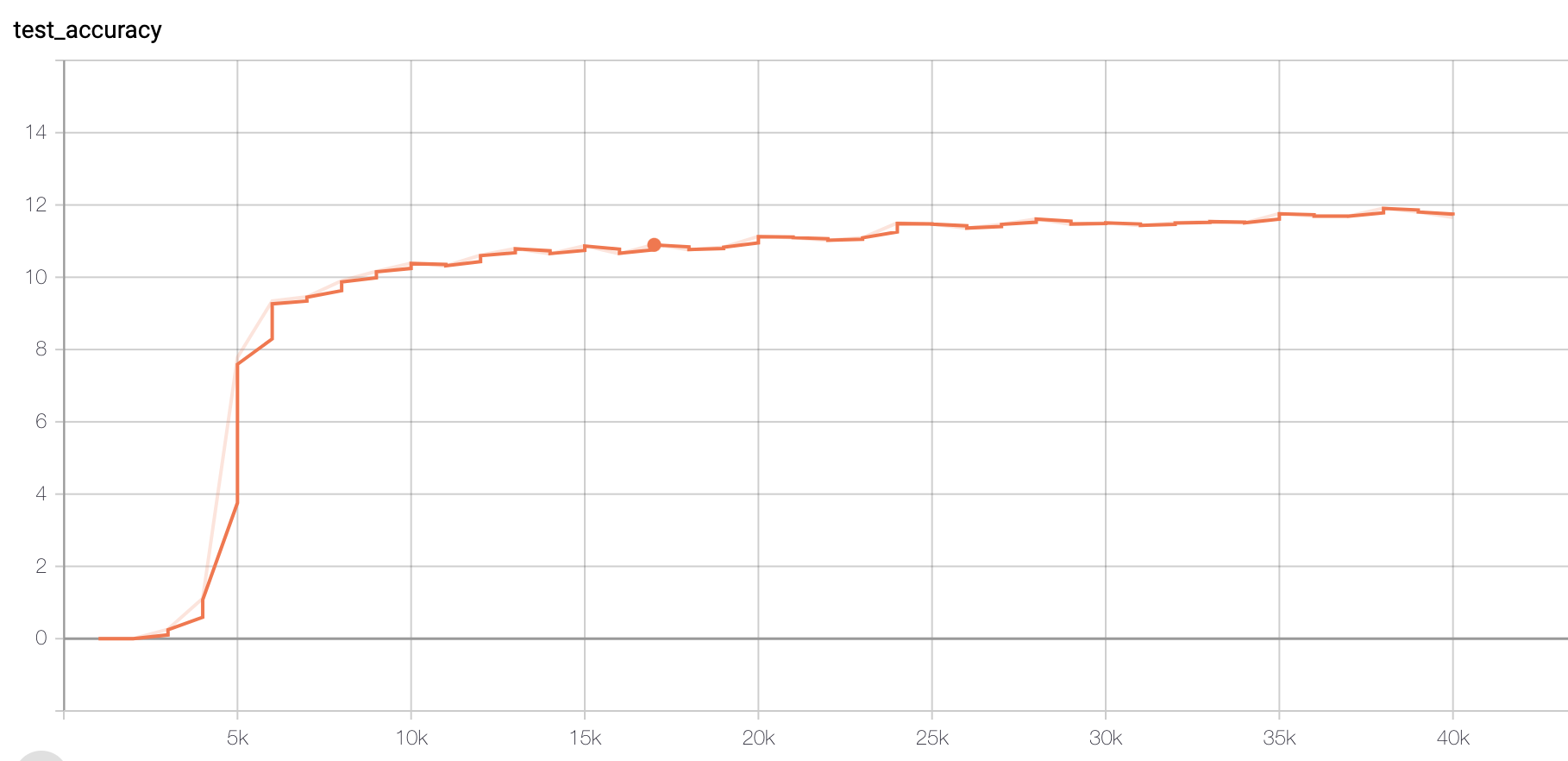
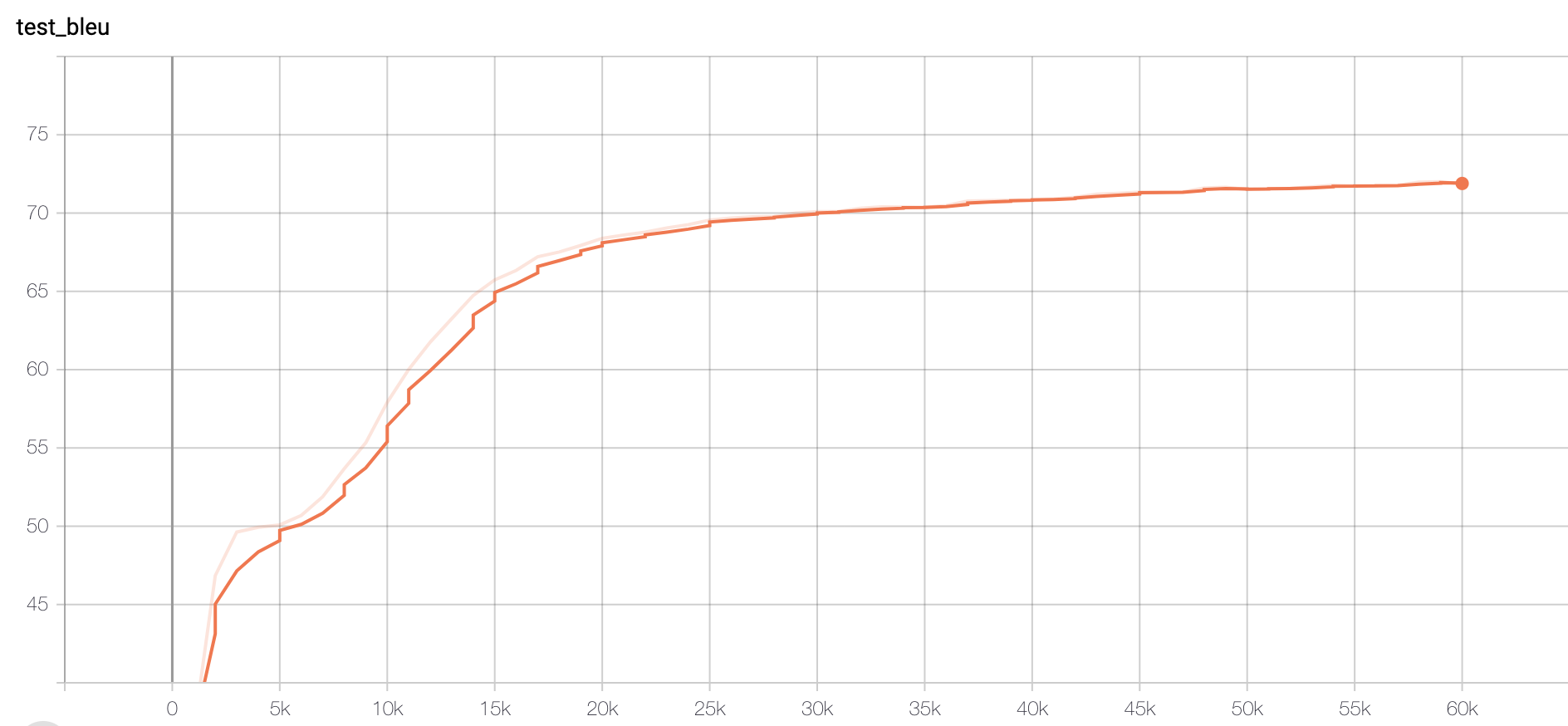
Figure 1. Accuracy of Original data set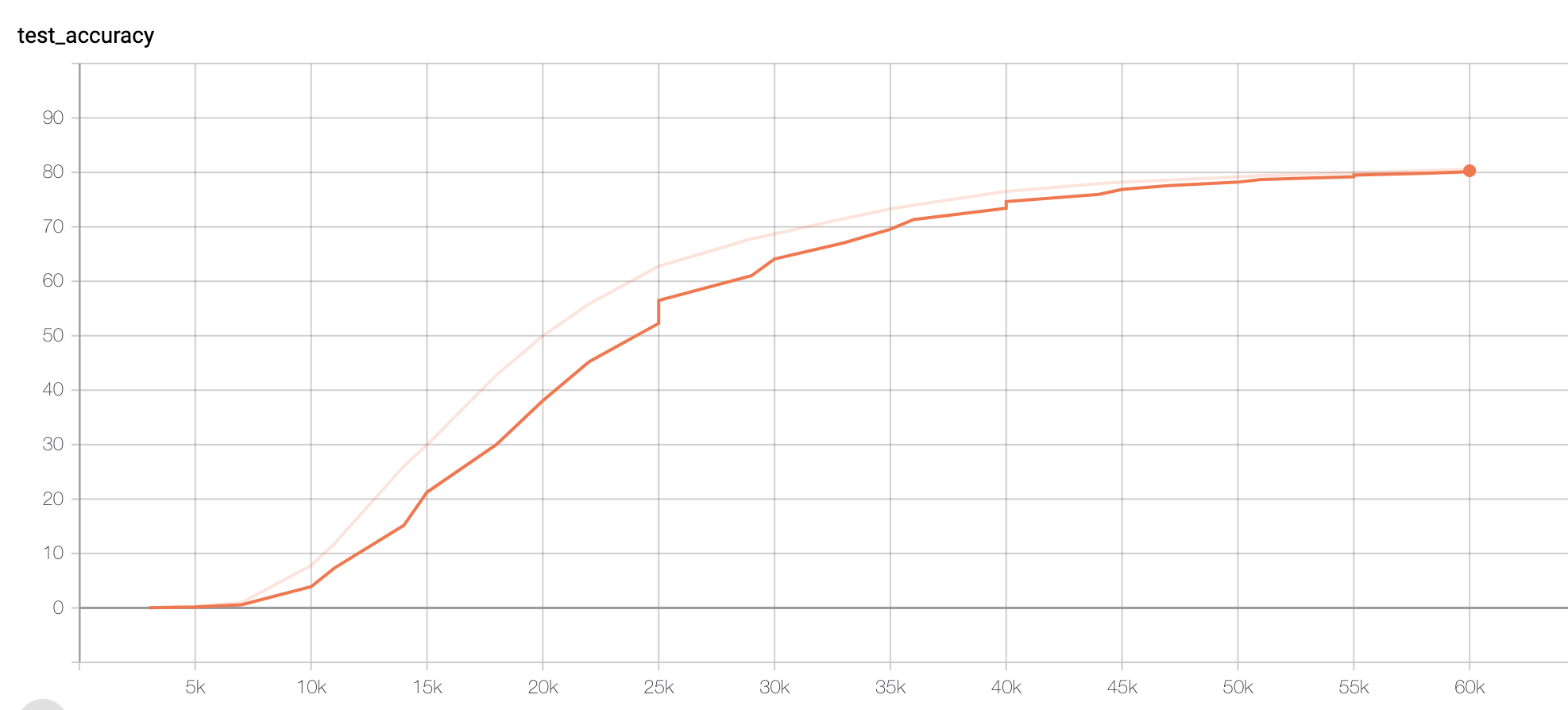
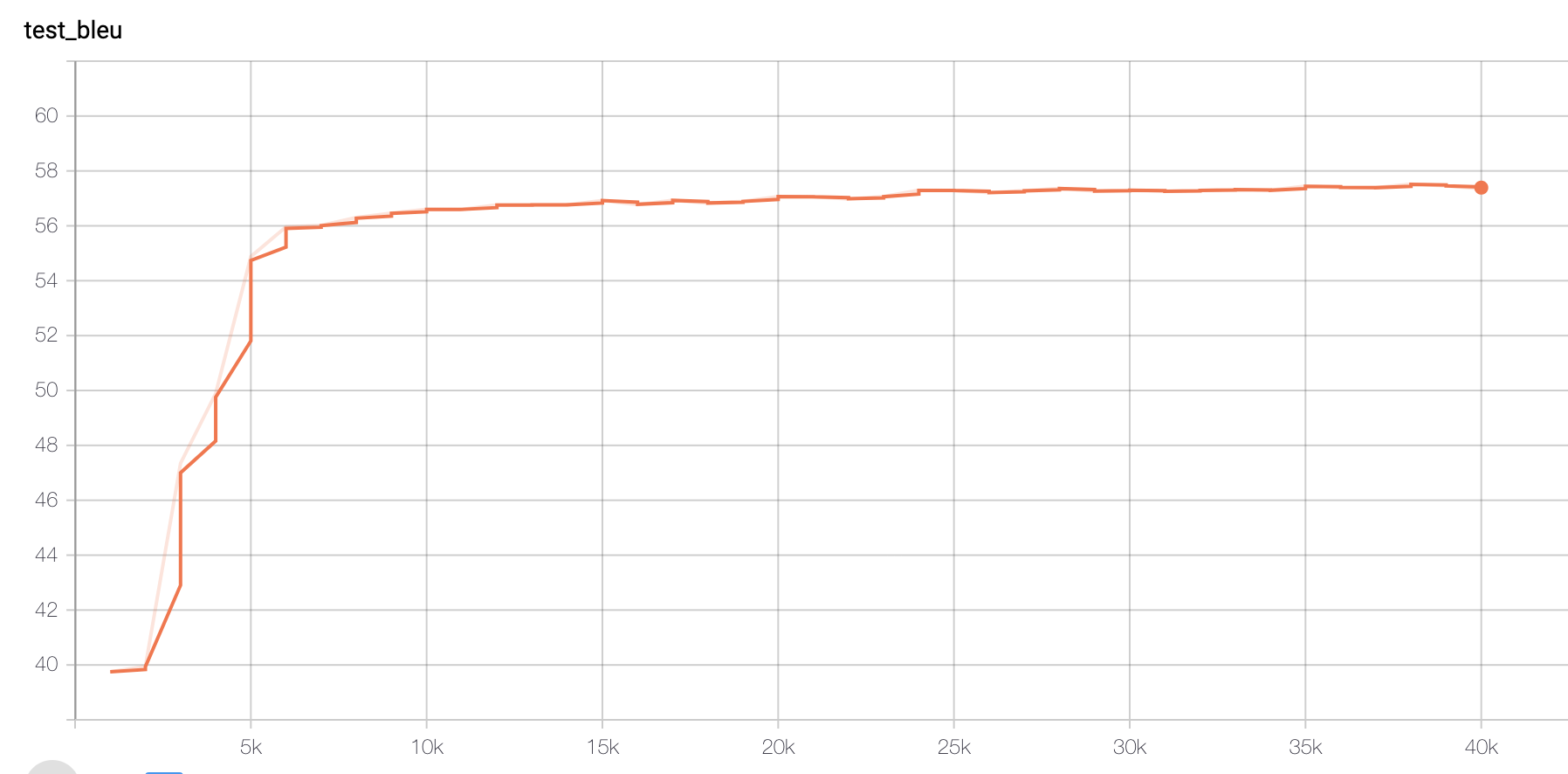
Figure 2. Accuracy of Paraphrased data set
We could see that Original (size tripled) data set could also reach a similar accuracy score (>70), except that it may require more training steps. The slower training could be explicated later.
However, when I tested the Paraphrased model on the original test set, the accuracy only gives 42. This result would be explicated in the next paragraph.
Other statistics
There are 587936 samples for each of the two data sets (Paraphrased and Tripled data sets), nearly 103000 entities appear in the two data sets, which means approximately 5 samples per entity on average, and this could ensure the final performance of the translation.
However, among the 103000 entities in the original data set, there are about 54000 entities that don’t appear in the Paraphrased data set. This means a different ensemble of entities between the two data sets and explicates the low accuracy of Paraphrased model on original test set. This line of code could show why there exists a difference.
Conclusion
As we have a such large ensemble of entities, each time of training will only pick a subset of them, we should encourage the Generator to pick a much bigger size of the subset in order to cover as many entities as we can. To realize that, we should change a little bit the code of priority here. Changing the 1~5 usages to the highest priority and 0 usage to the second could be better, as the number of samples per entity on average is 5 and this could ensure that the final accuracy reach 81, which is satisfactory. We should do an experiment if necessary.
Hypothesis 2
The second hypothesis is the basic idea of the Paraphraser: it could help match the relation/predicated by adding variation to the original templates
Experiment 2
As the accuracy is no longer a proper metric of evaluation, and the test set of the original data set is not a good choice neither because of the different ensemble of entities, I chose qald-9-test as a test set and count the number of matched relations. To be fair, I only picked single Basic-Graph-Pattern questions whose relation exists in out data set.
Results1
Among the 30 samples of simple BGP questions whose relation appears in the data set (qald-9-test), the Paraphrased model could match 9 of them correctly; whereas the Original model predicts 4 of them correctly. We could say that the Paraphraser double the final performance at the level of matching relations.
Results2
In a larger data set (qald-9-train), among about 100 samples, the paraphrased model could match correctly 40 relations, whereas the original model could only match 10 of them. There exists a huge improvement.
Other statistics
The synonym in the paraphrasing procedure is necessary to help with the performance, because we could not totally count on the embeddings to cover automatically the synonyms of expressions.
I have checked the cosine similarity of synonymous expression in our GloVe.6B.200d pre-trained embeddings and found:
“husband” and “spouse”
0.6033827158132323“wife” and “spouse”
0.5476363820234046“writer” and “author”
0.778833813581239“profession” and “occupation”
0.25730224462480544
These kind of “not similar” synonym pairs has caused many mis-matched relations. The performance of embeddings should be better to help with the synonyms, otherwise, the synonyms should be handled with Paraphraser.
Hypothesis 3
The Paraphraser could also help with the matching of entities.
Experiment 2
It’s the same experiment with the last one.
Result
Intuitively, this assumption is wrong because the Paraphraser only paraphrases templates, which means it doesn’t change any entities, so the matching of entities should be the same. In fact, I didn’t agree with this hypothesis neither at first, but here comes some results:
The prefixes are removed and some expressions are decoded to simplify the comparison
Natural Language question: “Who was influenced by Socrates?”
Ground True Query: “SELECT DISTINCT ?uri WHERE { ?uri dbo:influencedBy dbr:Socrates> }”
Original model: “SELECT ?uri WHERE { dbr:James_Allen_(Virginia_delegate) dbo:foundingYear ?uri }”
Paraphrased model: “SELECT ?uri WHERE { dbr:Socrates dbo:influencedBy ?uri }”
We could see that the paraphrased model predicts correctly both the relation and the entity, except for the order because our templates of SPARQL quries all follow the same order; whereas the original model predicts neither of them.
Natural Language question: “How many awards has Bertrand Russell?”
Ground True Query: “SELECT (COUNT(?Awards) AS ?Counter) WHERE { dbr:Bertrand_Russell dbp:awards ?Awards }”
Original model: “SELECT ?uri WHERE { dbr:KTPX-TV dbo:subregion ?Awards }”
Paraphrased model: “SELECT ?uri WHERE { dbr:Claude_Bertrand_(neurosurgeon) dbo:award ?Awards }”
We could see that the relation nearly matches, dbo:award with dbp:awards, and the paraphrased model catches part of the entity name Bertrand, where as the original doesn’t catch it at all.
Conclusion
The Paraphraser does help with the matching of entities, which is a little bit contradictory to intuition.
A further hypothesis is: The Paraphraser can help with the matching of entities only if the relation is correctly or almost correctly matched. This would be an interesting subject, but it’s harder to be proved, because we have such a large entities.