Introduction
In order to study the effect of generalization of Paraphraser, to make clear if it could help not only DBpedia increase the performance of a Question Answering system, I’ve decided to implement it to other knowledge bases.
Among all the choices: freebase, wikidata, yage, I’ve picked up Yago because of its similarity with DBpedia: uses an Endpoint of Sparql, maintain a clear schema, the range of most of properties are available, etc.
Implementation
Although Yago is similar with DBpedia in many ways mentioned above, I still need to modify many details of the code, in particularly on the step of creating the original templates and the step of Generator.
As the labels of properties are not accessible on the page of each class, the predicates could only be integrated into the original templates in a Bump Nomenclature way:
Normal way: What is the active years end year of “A” ?
Bump Nomenclature way: What is the activeYearsEndYear of “A” ?
Comparison
The two tests and training are all realised with a Bi-LSTM, 512-unit model, and 40k training steps.
Model I:Non Paraphrased Dataset
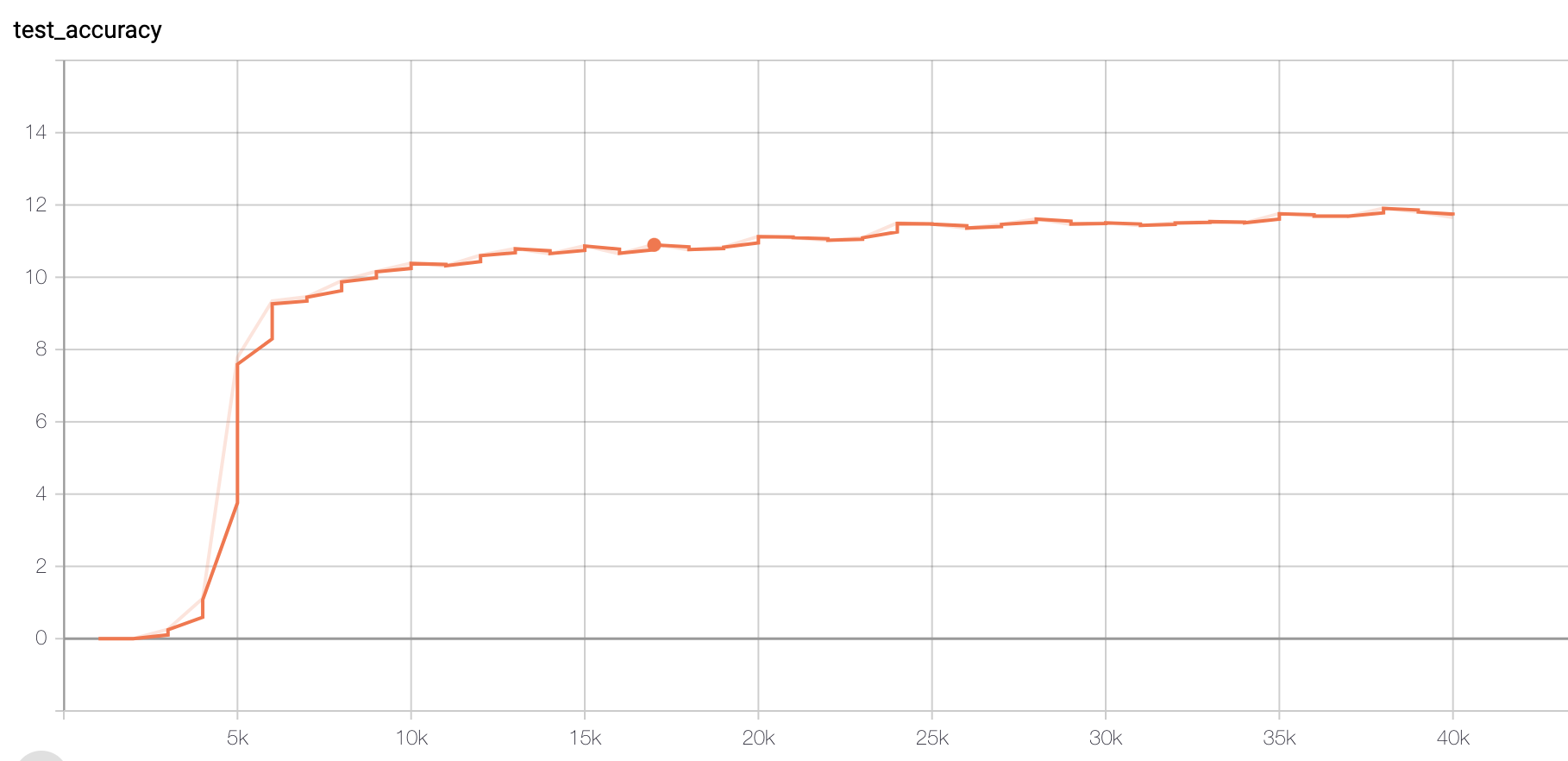
Figure 1 Accuracy
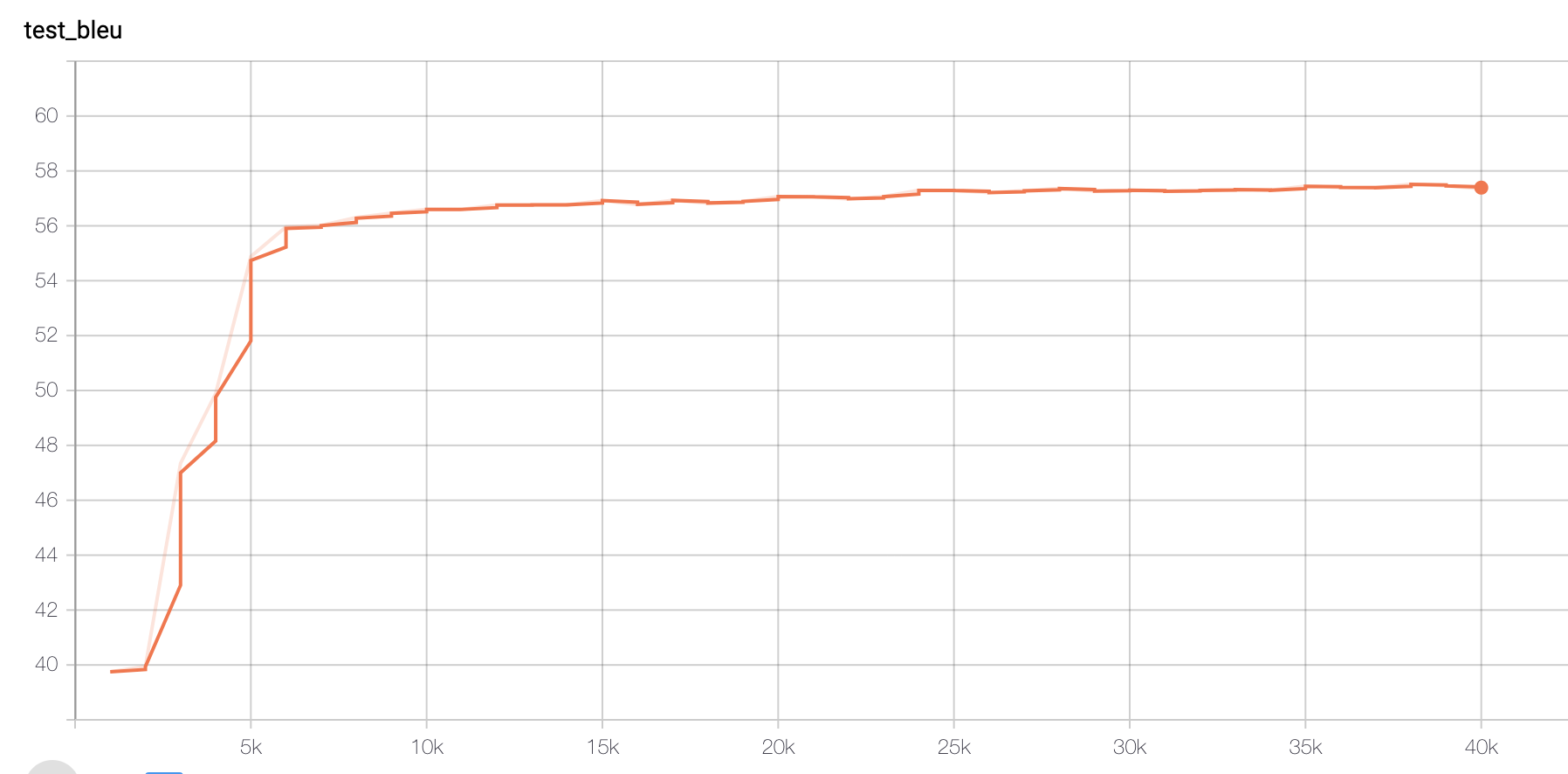
Figure 2 BLEU Score
The final accuracy on test set reaches 0.11653.
Model II: Paraphrased Dataset
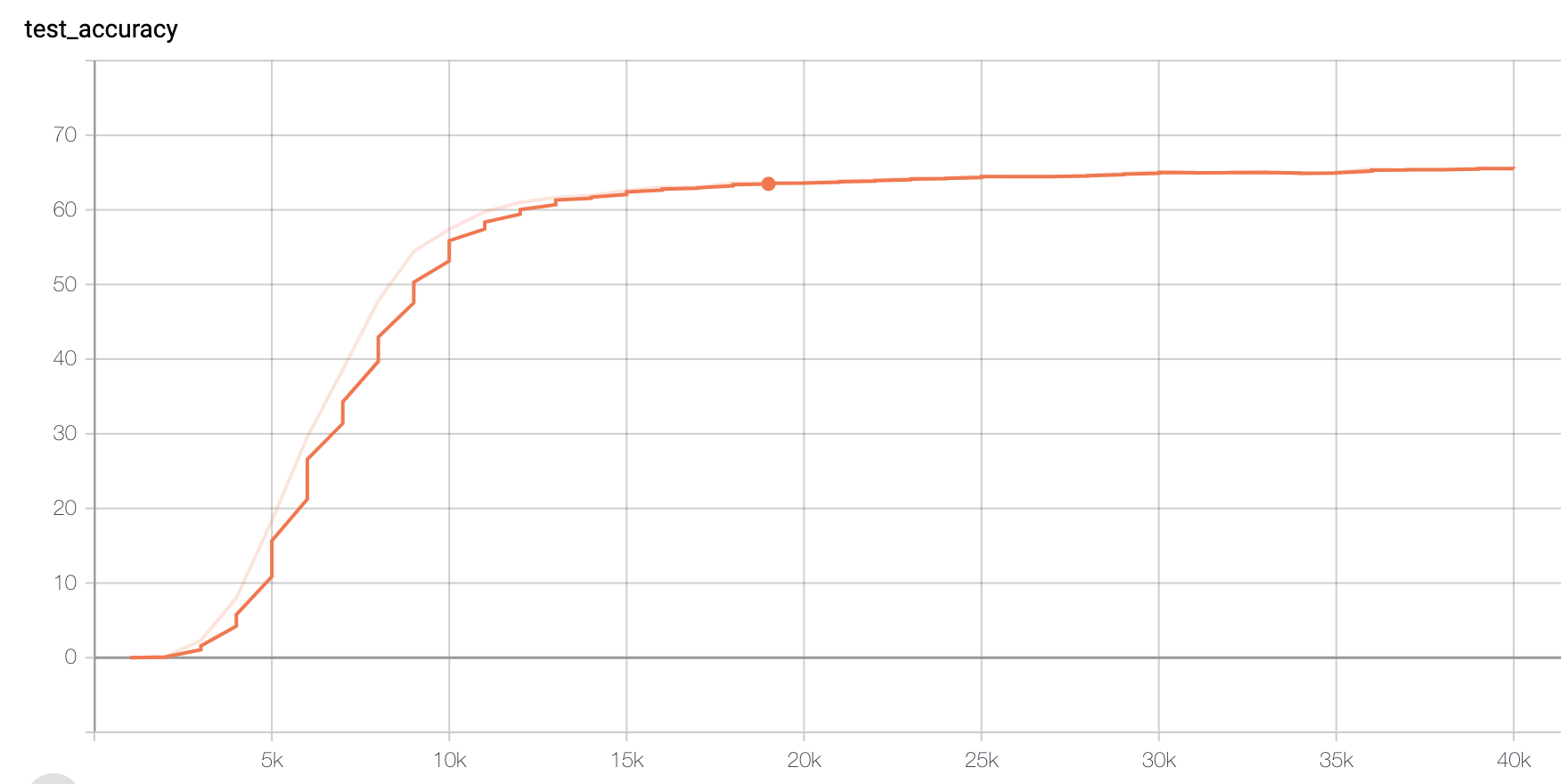
Figure 3 Accuracy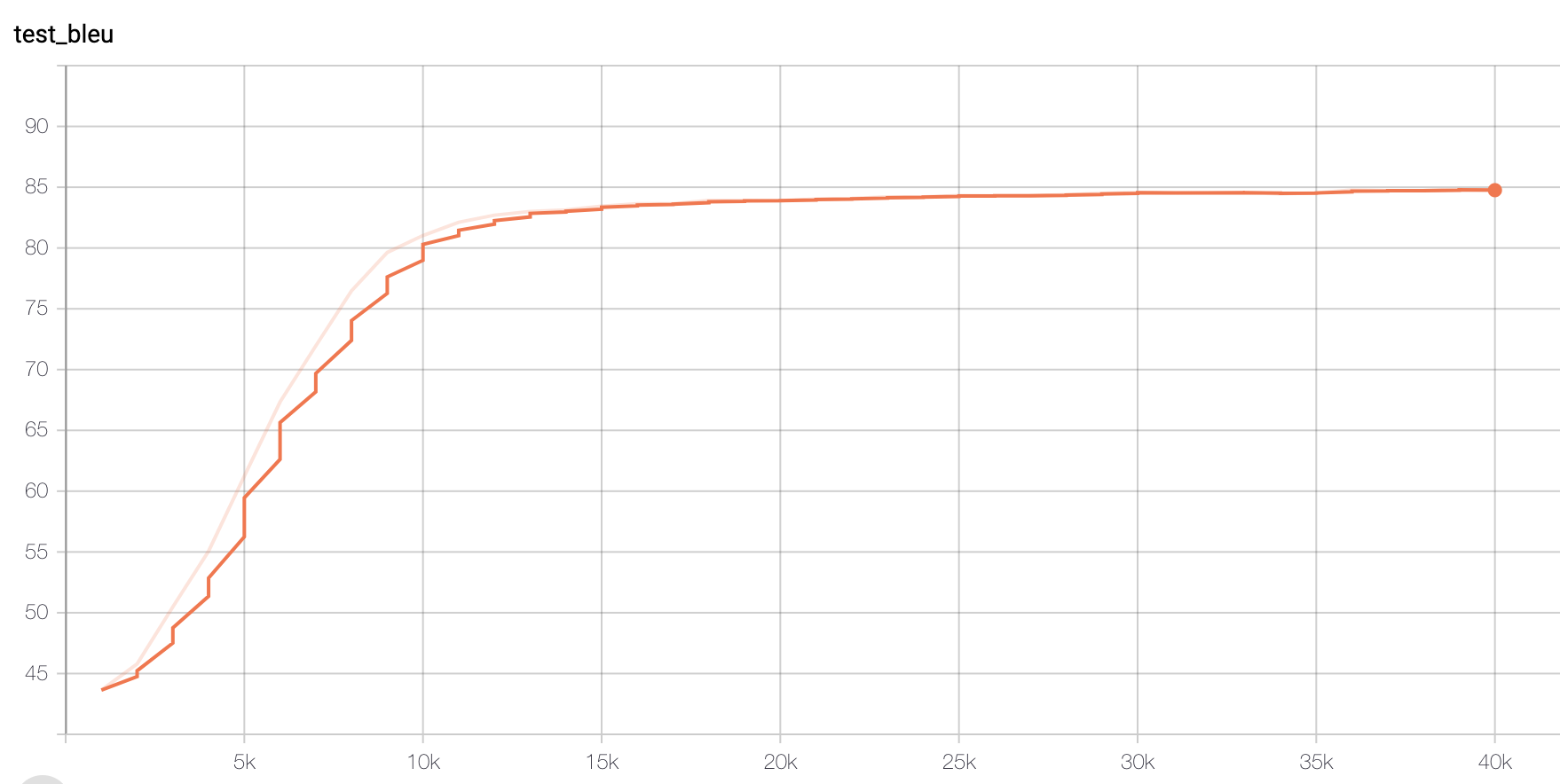
Figure 4 BLEU Score
The final accuracy on the same test set with Non paraphrased Data set (not the representation of Figure 3), reaches 0.72338, which is really surprising.
Conclusion
We could see a leap forward of accuracy from the non paraphrased on to the paraphrased one (from 0.12 to 0.72). This may be caused by the Bump Nomenclature of predicates, which increases the difficulty to the non paraphrased one to be learnt, while the paraphrased data set somehow deconstruct the Bump Nomenclature names and make it much easier to be learnt.